Aangemaakte reacties
-
AuteurBerichten
-
Dag damnsharp :),
Ik kan mij helemaal vinden in je redenering.
1. 2x ‘bed-breakfast’ in je url is inderdaad wat veel, hoewel ik niet verwacht dat Google hier een probleem van zal maken. Voor bezoekers ziet het er vooral spammy uit. En door ons te richten op de bezoekers, richten we ons ook op Google.
2. Als je meerdere agriturismo huisjes in Spanje hebt, zal je daar inderdaad een extra url-niveau voor moeten creëren.
3. Voor de voor jou belangrijke zoekterm ‘agriturismo’ heb je zodoende de pagina websitenaam.com/agriturismo/.
4. Voor de zoekterm ‘bed breakfast spanje’ heb je websitenaam.com/agriturismo/bed-breakfast-spanje/. Omdat de ‘bed-breakfast-spanje’-directory onder de ‘agriturismo’-directory valt, verwacht ik echter dat het lastig scoren wordt op puur ‘bed breakfast spanje’. Die pagina zal vooral relevant zijn voor ‘bed breakfast agriturismo spanje’ (in alle volgorden).
Het betreft toch de site https://www.vpn-review.org ?
Ga bijvoorbeeld naar de homepage, kijk in de bron van de pagina (ctrl+u in de chrome browser), zoek bijvoorbeeld op ‘<html’ en zie 5 matches.
Idem als je zoekt op ‘<head>’.
In de dev.tool van Chrome zie je inderdaad maar één head-sectie, namelijk de eerste. De rest wordt blijkbaar genegeerd in de DOM. Maar de tool van Patel kijkt naar de source en niet naar de DOM.
Hoewel Google naar de DOM kijkt, zou ik het probleem toch oplossen. Browsers kunnen bovendien ook vastlopen op dergelijke constructies. Via de w3c-validator zie je de fouten ook naar boven komen: https://validator.w3.org/nu/?doc=https%3A%2F%2Fwww.vpn-review.org%2F
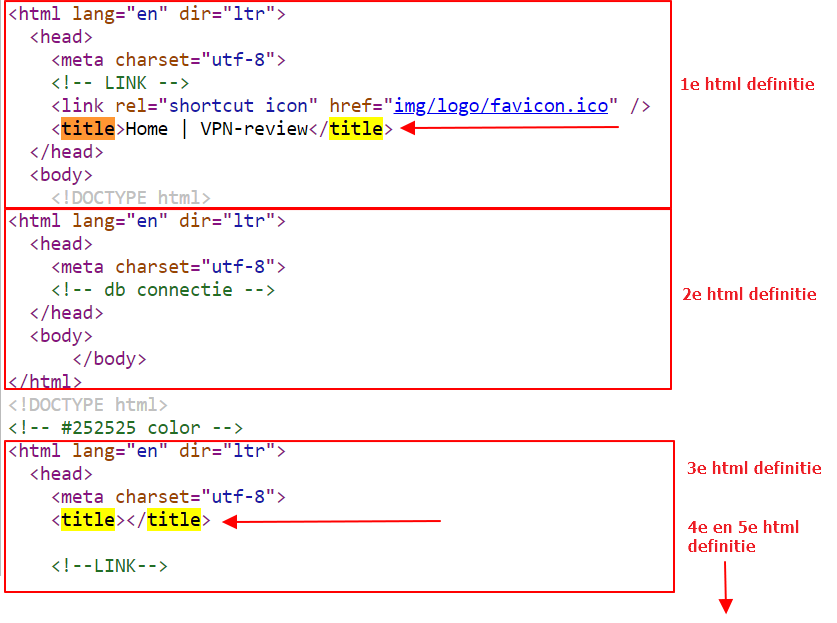
De tool meldt ‘herhalende title tags’ omdat de <titel> meerdere keren op de pagina voorkomt, daar waar je er één mag hebben (in de head-sectie van de pagina). Dit komt omdat je pagina’s compleet zijn geruïneerd. Het lijkt of de pagina vijf keer wordt gegenereerd, binnen één pagina, want er komt vijf keer een <head>-sectie voor. Zie afbeelding. Je zult er dus allereerst voor moeten zorgen dat er een pagina wordt gegenereerd met één head en één body. Dan zal er vanzelf ook één Title overblijven. Succes!
-
Deze reactie is gewijzigd 5 jaren, 2 maanden geleden door
Alain Sadon.
Er lijkt mij helemaal niets om van te schrikken. Natuurlijk bevat de site allemaal loops. De linkstructuur is nooit éénrichtingsverkeer. Links liggen alle kanten op, en Googlebot heeft daar ook geen enkel probleem mee. Integendeel, ze maken gebruik van die informatie. Zorg dat je belangrijke pagina’s prominent worden gelinkt (b.v. vanuit hoofdmenu of vanuit de main content van pagina’s).
Vuistregel: hoe minder klikken een pagina vanaf je homepage ligt, hoe meer kracht die krijgt.
Dag René,
Het is mij niet helemaal duidelijk welk probleem je precies probeert op te lossen. Het lijkt erop dat je je zorgen maakt over de interne links die er naar pagina’s liggen. Kort gezegd kan je stellen dat pagina’s meer scoringskracht krijgen als er meer interne links heen liggen. Daarom doen de pagina’s die vanuit het hoofdmenu bereikbaar zijn, ’t meestal relatief goed omdat die (via het menu) vanuit alle pagina’s gelinkt worden.
In reactie op je vragen, de volgende opmerkingen:
1. Ik begrijp dat je probeert te achterhalen hoeveel interne links een pagina bevat. Bij mijn weten kan dat niet via de Google Search Console (webmaster tools) worden ingezien. Daar zie je bij ‘Interne links’ alleen de links die er vanaf andere pagina’s (in je site) naar de betreffende pagina liggen. seoreviewtools.com kent inderdaad wel zo’n interne link analyzer.
Dat beide tools ook de links in het navigatiemenu en de widgets meenemen, lijkt mij logisch. Waarom zou je die willen uitsluiten?
2. Als je wilt weten welke links er vanuit de main content (dus de pagina-content, zonder navigatiemenu, widgets, footers, etc) naar een bepaalde pagina liggen, zou je de tool screaming frog kunnen gebruiken. Daar kan je namelijk via speciale instructies precies definiëren wat je wil. Ik heb eens zoiets gedaan voor de analyse van backlinks. Daarover kan je hier meer lezen.
Ik denk dat er vooralsnog geen reactie is gekomen, omdat geen specifieke SEO-vraag is. In jouw geval zou ik echter proberen te onderzoeken wie de bezoekers precies zijn. Misschien zijn er veel bots die de site raadplegen? Indien er weinig bezoekers op de site komen (ik ken immers niet de bezoekersaantallen) dan kom je door de bots al snel uit op een hoge bouncerate.
Graag gedaan!
Een homepage is -met oog op SEO- de pagina die je inzet voor de optimalisatie op je meest algemene (shorttail) zoektermen. Als de homepage alleen de berichten toont uit je blog, dan kan je die zoektermen niet expliciet in de content van de homepage opnemen. Meestal is dat een gemiste kans. Een statische homepage met eigen, unieke content en geoptimaliseerd op je shorttail-zoektermen is daarom normaal gesproken een betere oplossing. Op onderhavige site is dat ook zo opgelost.
Als je deze aanpassing doorvoert, zal Googlebot simpelweg de nieuwe content indexeren. De scoringskracht van de homepage/site wordt bepaald door de backlinks. Die veranderen niet, dus de scoringskracht blijft onveranderd. Bovendien is het gebruikelijk dat homepages dynamisch van inhoud zijn.
Ik zou zeggen:
Met op beide pagina’s de opties M en L
De eenvoudigste manier om de robots.txt te testen is via Google’s robots.txt tester: https://www.google.com/webmasters/tools/robots-testing-tool. Zorg dat je bent ingelogd in het juiste Google account en kies de juiste property. Vervolgens kan je verschillende cruciale pagina’s van je site als url invoeren en kijken of die geblokkeerd worden. Zo bevat je robots.txt de regel Disallow: /?. Dat betekent dat URL’s die /? bevatten gedisallowed worden. Misschien heb je bijvoorbeeld filter-pagina’s in je site die zodoende niet worden geïndexeerd?
Overigens zorgt een disallow in de robots.txt er niet voor dat die pagina uit de zoekresultaten wordt verwijderd. De instructie zorgt er slechts voor dat Google de inhoud van de pagina niet gaat bekijken. Als er veel links naar die pagina liggen kan Google (op basis van bijvoorbeeld de ankerteksten in de links) toch besluiten de pagina te tonen.
Dat is één, of eigenlijk twee, want dit betrof je tweede vraag. Je eerste vraag betreft de disallow van de iframe. Als je embeds onder */embed staan zorgt de Disallow: */embed er dus voor dat Google die inhoud niet gaat bekijken. Normaal gesproken zal Google proberen de inhoud van de embed bij pagina waar het iframe staat te indexeren, maar ik begrijp dat dit nog wel eens mis gaat (bij Google). Nu Google de inhoud van de iframe niet mag bekijken, zal Google niet weten wat de bezoeker wél mag bekijken. Normaal gesproken vindt Google dat niet fijn: zij willen zien wat de bezoekers ook zien. Ik zou deze disallow om die reden dus weghalen. Je zou ook in de Google Search Console (bij URL inspectie – Gecrawlde pagina bekijken – Meer informatie – Paginabronnen), kunnen kijken of Google een melding maakt over de robots.txt.
Borduren is een specifiek soort bedrukken. Je zou om die reden best het woord ‘bedrukken’ in je teksten kunnen opnemen, waarbij je uitlegt dat het hier om borduren gaat. Echter, omdát het om een specifieke vorm van bedrukken gaat, verwacht ik dat de pagina gematigd zal gaan scoren op ‘bedrukken’-gerelateerde zoektermen. Pagina’s die completer zijn in hun aanbod zullen vermoedelijk beter scoren.
Je hebt gelijk, er staan vele pagina’s in de index van Google die alleen verschillen in de plaatsnaam. Het verrast ook mij dat Google dit toelaat, m.a.w. dat deze oude SEO-strategie dus nog steeds werkt. Dank voor de info!
Welke site en welke pagina’s betreft het? Dan kan ik even kijken.
Je moet even checken of Google die pagina’s ook allemaal indexeert. Ik vermoed namelijk van niet. Dat kan je checken door in Google te zoeken op een stukje representatieve tekst, inclusief een plaatsnaam. Dan kan je dus zien of betreffende pagina in de zoekresultaten verschijnt. Je kan het ook checken via het cache:-commando op een aantal van die pagina’s.
Google geeft niet zo snel een penalty. In plaats daarvan negeert Google simpelweg de pagina’s die (nagenoeg) identiek zijn.
Ik ga ervan uit dat zoekwoord+locatie inderdaad automatisch ‘meelift’ op de vindbaarheid op het zoekwoord alleen, mits de naam van de locatie ook op de pagina voorkomt.
Je zou in de praktijk kunnen uittesten wat de effecten zijn van het alleen noemen van de locaties op de betreffende pagina’s, d.w.z. of de vindbaarheid op zoekwoord+locatie dan al voldoende gerealiseerd wordt.
Als dat niet het geval blijkt, dan zou je aparte pagina’s kunnen maken, die je optimaliseert op zoekwoord+locatie. Die pagina’s link je dan vanuit de pagina die goed scoort op het zoekwoord (alleen).
Maar als het veel zoekwoorden en locaties betreft, is dit niet de ideale oplossing omdat het lastig wordt unieke content te realiseren voor iedere zoekwoord/locatie pagina. Ik zou daarom in principe alleen de namen van de locaties opnemen op de zoekwoord-pagina’s.
-
Deze reactie is gewijzigd 5 jaren, 2 maanden geleden door
-
AuteurBerichten


Gerelateerde berichten:
- Google Analytics alternatieven 23 december 2024 Hi allemaal, ik ben op zoek naar alternatieven voor GA4 om organische omzet te meten. Hebben jullie aanbevelingen? Dankjewel!