 Het vak ‘SEO voor tekstschrijvers’ is enorm geëvolueerd de laatste jaren, met name vanwege de stormachtige ontwikkelingen op het gebied van de Machine Learning. Via dit artikel zal ik uitleggen hoe dit werkt. Het is niet eenvoudig, maar wel zó wezenlijk, dat ik meen dat webtekstschrijvers (en wie is dat niet?) hiervan op de hoogte zouden moeten zijn.
Het vak ‘SEO voor tekstschrijvers’ is enorm geëvolueerd de laatste jaren, met name vanwege de stormachtige ontwikkelingen op het gebied van de Machine Learning. Via dit artikel zal ik uitleggen hoe dit werkt. Het is niet eenvoudig, maar wel zó wezenlijk, dat ik meen dat webtekstschrijvers (en wie is dat niet?) hiervan op de hoogte zouden moeten zijn.
We zullen zien dat de vele claims die seo-specialisten doen, en de seo tools die we gebruiken om onze teksten te optimaliseren, over-gesimplificeerd zijn. Moderne tekst-optimalisatie kan niet worden begrepen zonder iets te begrijpen van de vraag hoe systemen überhaupt intelligent kunnen zijn. Ik heb het verhaal in een paar logische stappen, met duidelijke voorbeelden, opgebouwd. Het in de aard technische verhaal is geschreven voor tekstschrijvers, dus mensen die niet technisch geschoold zijn (maar wel snappen dat ze iets van de techniek zouden moeten weten). Ik lees in de comments graag hoe ver je bent gekomen 😊.
Stap 1: De basis
Een goed geoptimaliseerde tekst is een tekst waarvan Google meent dat die tekstueel goed aansluit bij de zoekopdracht. Het vakgebied in de informatica waar oplossingen worden bedacht voor de vraag hoe je zoekopdracht en tekst kan matchen, wordt Information retrieval systems genoemd. Want hoe doe je dat? Je moet op basis van slechts een paar woorden in de zoekopdracht bepalen in hoeverre een grote verzameling teksten daar al dan niet goed bij aansluiten.
In het begin, en dan spreek ik over eind jaren ’90 tot zelfs een paar jaar geleden, waren dit de belangrijkste basisregels:
- De woorden uit de zoekopdracht moeten in de tekst aanwezig zijn (dichtheid > 0), maar niet zó vaak dat er van spam sprake lijkt. Keyword density wordt dat genoemd. Er bestond en bestaat geen optimale dichtheid.
- Hoe prominenter de woorden uit de zoekopdracht in de tekst aanwezig zijn (d.w.z. hoe eerder de woorden in de tekst genoemd worden), hoe relevanter de tekst voor de zoekopdracht. Keyword prominence wordt dat genoemd.
- Hoe exacter de zoekopdracht in de tekst aanwezig is, hoe relevanter de tekst voor de zoekopdracht. Als de zoekopdracht [lekkere pizza] is, en het woord ‘lekkere’ aan het begin van de tekst staat en ‘pizza’ aan het eind, dan is dat minder exact dan wanneer ‘lekker pizza’ naast elkaar geschreven in de tekst staat. Keyword proximity wordt dat genoemd.
Ook al zitten we inmiddels in 2020, voorgaande basisregels zijn nog steeds geldig, dus pas die ook zo toe in de tekst. Maar inmiddels is er veel meer aan de hand.
Stap 2: Zoekopdrachten en teksten worden vertaald naar reeksen van getallen
Je moet weten dat de systemen die teksten en zoekopdrachten proberen te matchen, deze allereerst vertalen naar getallen, of eigenlijk: reeksen van getallen. De grootte van de reeks is het aantal woorden dat onze taal rijk is (anders gezegd: de grootte van ons vocabulaire). Als onze taal uit een miljoen verschillende woorden bestaat, dan is de reeks dus 1 miljoen getallen lang. Ieder woord uit de Nederlandse taal krijgt vervolgens een vast plekje in de reeks. Dat zou zoiets kunnen zijn (de #-getallen boven in de blokjes zijn simpelweg volgnummers in de reeks):

Een zoekopdracht als ‘leren schoenen’ wordt dan vertaald naar de volgende reeks:

En een zoekopdracht als ‘leren vintage schoenen’ wordt dan vertaald naar deze reeks:

Je kan je voorstellen dat ook de teksten die we schrijven, vertaald kunnen worden naar zo’n reeks. Omdat teksten uit veel meer woorden bestaan dan de zoekopdrachten krijgen we dus eenvoudigweg méér enen in de reeks (dan bij een zoekopdracht).
Ok, als je dit begrijpt kunnen we nu over naar de volgende stap…
Stap 3: Van reeksen van getallen naar vectoren
De reeksen kunnen wiskundig worden weergegeven via -wat genoemd wordt- vectoren. Dat is een begrip uit de lineaire algebra. Omdat er gerekend kan worden met vectoren (je kan ze optellen, aftrekken, vermenigvuldigen, etc.) kan je nu opeens ook gaan rekenen met woorden en teksten!
Als we de volgnummers in de reeks beschouwen als de coördinaten van het uiteinde van een pijl (een vector is eigenlijk gewoon een pijl met een bepaalde lengte in een bepaalde richting), dan ontstaat vanzelf de vector.
‘Leren schoenen’ schrijven we in vectornotatie als (0, …, 0, 1, 0, …, 0, 1, 0, …, 0), waarbij de enen op positie 8787 en 999656 staan. Deze miljoen-dimensionale ruimte kunnen we ons echter niet voorstellen. Daarom is het eenvoudiger even naar tweedimensionale vectoren te kijken.
Omdat er nu twee dimensies zijn, bestaat het vocabulaire dus ook uit twee woorden. In het volgende voorbeeld zien we een ruimte die opgebouwd is uit twee woorden ‘x’ en ‘y’, met daarin twee vectoren (a en b):
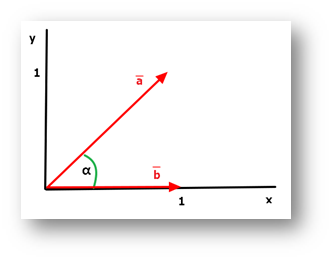
Laten we zeggen dat vector a de tekst voorstelt en vector b de zoekopdracht. De zoekopdracht was dan dus blijkbaar [x] (ik geef zoekopdrachten aan met rechte haken) en de tekst “x y”, of misschien “y x”.
Je kan je voorstellen dat de hoek tussen de twee vectoren (aangeduid door α) iets zegt over de mate waarin de twee vectoren iets met elkaar te maken hebben. Als de hoek 0 graden is, dan hebben ze alles met elkaar te maken. Als de hoek 90 graden is (vectoren loodrecht op elkaar), dan hebben ze niets met elkaar te maken. Omdat de hoek in de afbeelding 45 graden is, hebben de twee dus iets met elkaar te maken.
In werkelijkheid hebben we niet twee, maar een miljoen dimensies. Dit is natuurlijk niet te tekenen, maar voor de wiskundige berekeningen is het hoge aantal dimensies geen enkel probleem. Er kan gemakkelijk een hoek berekend worden tussen een één-miljoen-dimensionale zoekopdracht en een één-miljoen-dimensionale tekst. En dan geldt nog steeds: hoe kleiner de hoek, hoe groter de match.
Ok, nu hebben we weer een grote stap gemaakt. Tot een paar jaar geleden werkte het matchen van zoekopdracht en tekst op precies deze wijze: hoe kleiner de hoek, hoe beter je scoorde met de tekst. Maar we zitten anno 2020 vol in het tijdperk van de Artificiële Intelligentie. Hoe kan in zo’n saai, wiskundig vectormodel nu intelligentie worden ingebracht? Dat gaan we ontdekken in de volgende stap…
Stap 4: Naar intelligentie
Om de volgende stap te kunnen maken moeten we eerst begrijpen waarom het hiervoor beschreven -laat ik het maar noemen- traditionele vectormodel niet intelligent is. Als er gezocht wordt op ‘beeldbuis’ en de tekst bestaat alleen uit de tekst ‘tv’, dan is de hoek tussen de vectoren 90 graden (ieder woord heeft immers een eigen dimensie), terwijl een intelligent systeem zou moeten begrijpen dat de twee termen wel degelijk met elkaar te maken hebben: de hoek zou voor een intelligent systeem veel kleiner dan 90 graden moeten zijn.
Conclusie: bij een intelligent systeem zouden de woorden niet allemaal een eigen dimensie moeten krijgen. Want dan hebben de verschillende woorden niets met elkaar te maken. De dimensies zouden iets anders moeten betekenen.
En precies dát kunnen we bewerkstelligen via neurale netwerken. Neurale netwerken, of eigenlijk moet ik zeggen artificiële neurale netwerken (ANN’s), worden getraind door ze een enorme set van teksten te laten zien. Feitelijk wordt het ANN geleerd om ontbrekende woorden te voorspellen, als het slechts een deel van de zin te zien krijgt. Het ANN doet dit, en dat is belangrijk, door abstracties te maken. De hoeveelheid abstracties die het kan maken wordt vooraf geconfigureerd (ingesteld). Een gebruikelijke instelling is 300 abstracties. Uiteindelijk is het getrainde systeem in staat om alle woorden uit te drukken in termen van deze abstracties.
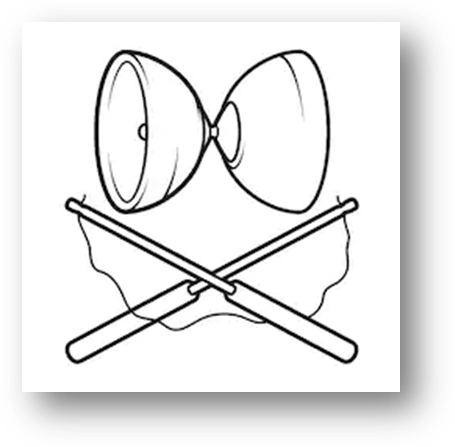 Zie het ANN als een diabolo. Helemaal links (dat is de input) staan alle woorden uit het vocabulaire en helemaal rechts (dat is de output) ook. De grootte van de openingen is dus voldoende voor een miljoen woorden. Om een woord van input naar output te brengen moet dat via het smalle middenstuk. De grootte van het middenstuk heeft echter slechts ruimte voor 300 woorden. Dat kan alleen als het geen woorden zijn, maar abstracties over woorden. Het ANN is intrinsiek in staat om die abstracties te bepalen. Als we uiteindelijk ‘tv’ links aanbieden, zal -door die abstracties- rechts een waaier aan woorden geactiveerd worden. Dat zal het woord ‘tv’ zelf zijn, maar ook het meervoud en ‘beeldbuis’, misschien ook ‘monitor’ of zelfs ‘philips’ en ‘samsung’. Hoe kleiner de opening is, hoe moeilijker het wordt een oplossing te vinden voor alle woorden, maar hoe beter de abstracties. Hoe groter de opening wordt, hoe makkelijker het is, maar hoe zwakker de abstracties.
Zie het ANN als een diabolo. Helemaal links (dat is de input) staan alle woorden uit het vocabulaire en helemaal rechts (dat is de output) ook. De grootte van de openingen is dus voldoende voor een miljoen woorden. Om een woord van input naar output te brengen moet dat via het smalle middenstuk. De grootte van het middenstuk heeft echter slechts ruimte voor 300 woorden. Dat kan alleen als het geen woorden zijn, maar abstracties over woorden. Het ANN is intrinsiek in staat om die abstracties te bepalen. Als we uiteindelijk ‘tv’ links aanbieden, zal -door die abstracties- rechts een waaier aan woorden geactiveerd worden. Dat zal het woord ‘tv’ zelf zijn, maar ook het meervoud en ‘beeldbuis’, misschien ook ‘monitor’ of zelfs ‘philips’ en ‘samsung’. Hoe kleiner de opening is, hoe moeilijker het wordt een oplossing te vinden voor alle woorden, maar hoe beter de abstracties. Hoe groter de opening wordt, hoe makkelijker het is, maar hoe zwakker de abstracties.
De grote truc is nu dat deze abstracties de dimensies worden van ons nieuwe vectormodel, waarbij alle woorden uit ons vocabulaire in deze 300-dimensionale ruimte gepositioneerd zijn.
Het woord ‘tv’ is dan bijvoorbeeld een beetje abstractie 1, een beetje meer abstractie 2, helemaal niets van abstractie 3, etc. t/m abstractie 300. Het woord ‘beeldbuis’ zal dan een vergelijkbare verdeling krijgen. Als we weer even kijken naar de vorige figuur, dan zijn x en y in deze intelligente benadering dus geen woorden meer, maar abstracties over woorden. Hierdoor zullen de vectoren van ‘beeldbuis’ en ‘tv’ (die wordvectors worden genoemd) niet meer loodrecht op elkaar staan (d.w.z. niets met elkaar te maken hebben), maar ergens heel dicht bij elkaar in de buurt komen te liggen (d.w.z. heel veel met elkaar gemeen hebben).
Om dit nog wat verder te illustreren volgt hier een voorbeeld van een (platgeslagen) vectorruimte waar we allerlei woorden zien staan. Waar de woorden in het traditionele vectormodel willekeurig verdeeld zijn over de vectorruimte, zie je dat de woorden via een ANN getraind vectormodel zich op betekenis gaan groeperen. De gekleurde bolletjes zijn eigenlijk de uiteinden van de bij de woorden behorende wordvectors, die zélf -voor de overzichtelijkheid van het plaatje- zijn weggelaten:
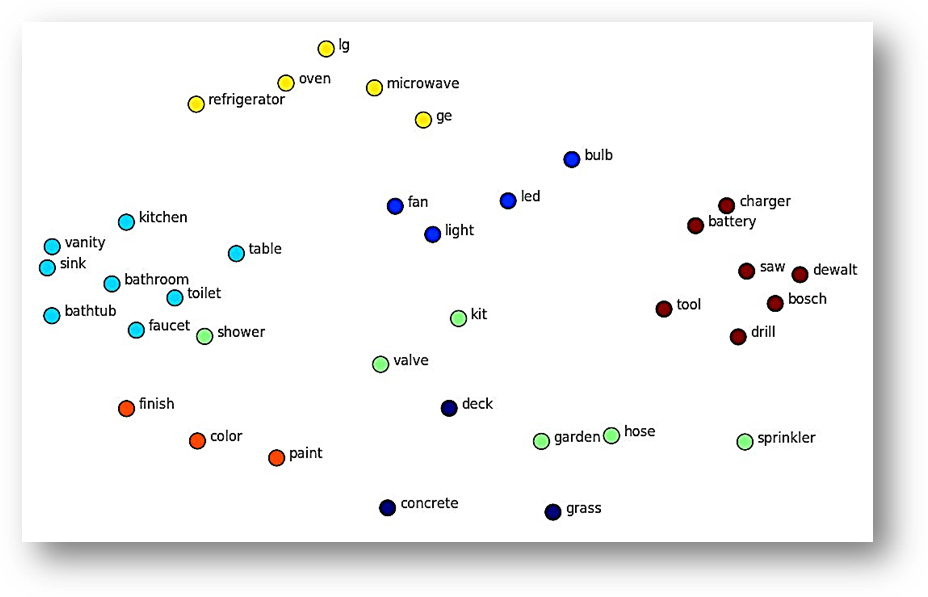
Hier zien we dus dat allerlei zelfstandig naamwoorden zich groeperen op betekenis. In dit plaatje zien we dat niet, maar hetzelfde vindt plaats voor werkwoord-vervoegingen, enkel-/meervoudsvormen, synoniemen, verbuigingen, etc.
Maar de intelligentie zit zelfs nóg wat dieper.
Hier zien we nog een (binnen de literatuur veelgebruikt) voorbeeld van een (wederom via een ANN getraind) vectormodel, nu weergegeven in 3 dimensies (dus drie abstracties) met vier woorden:
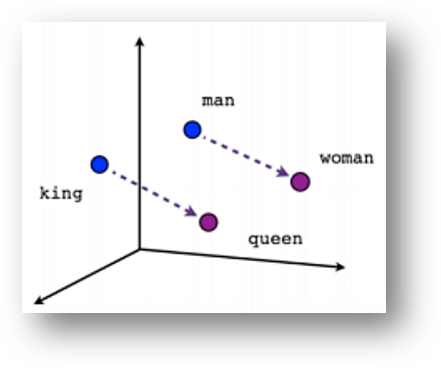
De intelligentie is nu hierin te herkennen dat het systeem begrijpt dat een ‘king’ zich tot een ‘queen’ verhoudt, zoals een ‘man’ zich tot een ‘woman’ verhoudt, omdat de richting van de paarse verbindingspijlen identiek is. Hetzelfde geldt voor werkwoordsvormen (‘walking’ verhoudt zich ‘walked’ als ‘swimming’ zich verhoudt tot ‘swam’) en landen met hun hoofdsteden (‘Ankara’ verhoudt zich tot ‘Turkey’ als ‘Berlin’ tot ‘Germany’):
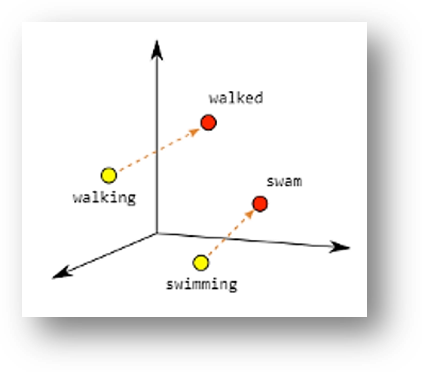 |
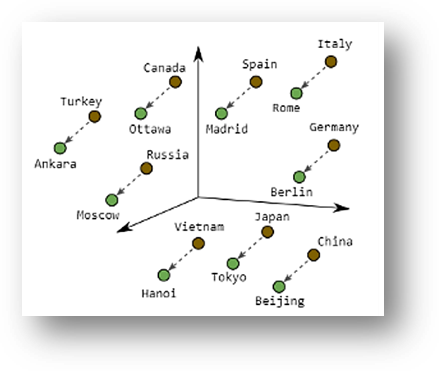 |
Bron van de afbeeldingen
Laatste stap: De volgorde van woorden
Tot slot wil ik nog zeggen dat zelfs dit slimme model nog een belangrijke beperking kent. Als we via dit model de zoekopdracht en de tekst gaan matchen dan speelt de volgorde van woorden (in de zoekopdracht zowel als de tekst) geen rol. De hoek die de vector van de zoekopdracht [leren schoenen] (die overigens geconstrueerd wordt uit de twee wordvectors van ‘leren’ en ‘schoenen’) met een bepaalde tekst maakt is dezelfde als [schoenen leren]. Nu is dat bij deze woorden niet zo’n probleem, maar als de zoekopdracht [goedkoopste vlucht amsterdam naar parijs] is, dan is de volgorde van woorden cruciaal (je wilt dan geen aanbieders te zien krijgen die reizen van Parijs naar Amsterdam aanbieden). Ik beperkt mij nu te zeggen dat Google daar vorig jaar ook een oplossing voor heeft gevonden. Het beschreven ANN is daarmee nog een stapje complexer geworden. De technologie hierachter heet BERT. Maar hiermee weten we nu wel alles wat we moeten weten als SEO-tekstschrijvers.
Wat betekent dit alles voor de praktijk van het seo tekstschrijven?
Leuk al die theorie, maar hoe kunnen we deze vertalen naar de praktijk van het tekstschrijven? In het hiernavolgende ga ik ervan uit dat we zo goed mogelijk gevonden willen worden op zoekterm A. Puntsgewijs zal worden uiteengezet waar we allemaal op moeten letten.
- Zorg dat de keyword prominence (zoekterm A zoveel mogelijk aan begin van de tekst) en keyword proximity (individuele woorden uit de zoekterm A bij elkaar houden in de tekst) goed zijn.
- Google is goed in staat meervoud/enkelvoud-varianten, verbuigingen en synoniemen met elkaar te verbinden. We hoeven dus niet voor alle mogelijke vormen en varianten van A een aparte pagina te schrijven. Als A=[vaatwasser], neem ‘vaatwasser’ dan in de tekst op. Je hoeft geen aparte pagina te schrijven voor bijvoorbeeld een synoniem als ‘afwasmachine’. Je zou het synoniem wel ook in de pagina zélf kunnen opnemen, maar zelfs dat is niet noodzakelijk om toch op het synoniem te kunnen scoren. Voor de leesbaarheid van de tekst is het vaak wel goed om ook synoniemen te gebruiken. Hetzelfde geldt voor werkwoordsvormen (‘gebruikte kleding’ vs ‘kleding gebruikt’) en meervoud/enkelvoud (‘seo trainingen’ vs ‘seo training’): Google zal de verschillende varianten verbinden waardoor je niet al die varianten in je tekst hoeft op te nemen.
- Als woorden in onze tekst dicht in de buurt liggen van het woord A (zoals in de figuur hiervoor ‘Madrid’ en ‘Spain’ dicht bij elkaar in de buurt liggen, of ‘battery’ en ‘charger’), dan zal een tekst met het ene woord vindbaar worden als gezocht wordt op het andere. Echter: hoe dichter de woorden bij elkaar liggen (synoniemen bijvoorbeeld), hoe beter de match en hoe beter we kunnen scoren. Om de pagina ook vindbaar te maken op meer woorden dan alleen A, kan ik wel aanbevelen om de woorden die in buurt liggen van A ook in de tekst op te nemen. Mogelijk verbetert dit ook het scoren op A.
- De volgorde van woorden wordt door Google begrepen (BERT), zowel in de zoekopdracht als in onze tekst. Een reis van Madrid naar Amsterdam is dus iets anders dan een reis van Amsterdam naar Madrid. Indien een verandering van de volgorde van de woorden in A leidt tot een andere betekenis, zorg dan dat de volgorde van woorden in A ook zo in de tekst gehandhaafd blijft.
Concluderend kunnen we stellen dat, door alle ontwikkelingen bij Google, het vak van SEO-tekstschrijver nu veel vrijer is geworden dan tot een paar jaar geleden. Het is nog steeds van belang een zoekwoordanalyse uit te voeren en de gevonden woorden in de tekst te gebruiken. En gebruik daarbij ook woorden waarvan je vermoedt dat die dicht in de buurt liggen van de woorden waarop je wilt scoren. Maar voel je vooral vrij om rond de zoektermen een zo mooi mogelijk tekst te schrijven. Veel meer dan vroeger kan je je focussen op de lezers van je tekst: die moeten de tekst waarderen.
Meer info: